
공부할 게 정말 많아서... 좋다 😇
| 딥러닝 | 비교 | 머신러닝 |
| 인공 신경만 이용 | 기반 기술 | 기존 통계 기법 기반 |
| 자동으로 특징 추출 및 이를 기반으로 학습 | 학습 | 미리 정의된 특징 추출 및 이를 기반으로 학습 |
| 대량 데이터 | 필요 데이터 | 비교적 간단한 데이터 |
| 복잡한 모델에서 높은 예측 성공 | 예측 성능 | 간단한 모델에서도 높은 예측 성공 |
| 이미지, 음성, 자연어 처리 분야에서 뛰어난 성능 | 활용 분야 | 다양한 분야 활용 |
| 전문 지식 필요 | 모델 설계 필요 지식 | 전문적 지식 필요 없음 |
| 오랜 학습 시간 | 학습 시간 | 빠른 학습 시간 |
| 복잡한 계산식 필요 | 계산식 | 복잡한 계산식 불필요 |
머신러닝 공격기법

■ 적대적 공격 2024.10.20 - [공부/AI] - LLM의 보안 취약성과 적대적 공격
- 머신러닝 엔진이 스스로 잘못된 판단을 하도록 유도하며, 딥 러닝의 심층 신경망을 이용한 모델에 적대적 교란(Adversarial Pertubation)을 적용하여 오분류를 유발하고 신뢰도 감소를 야기함
- 공격목적 = 인공지능이 잘못된 의사결정을 하도록 만듦
(1) 신뢰도 감소 (Confidence reduction)
모델에 대한 예측 신뢰도를 감소
(2) 오분류 (Misclassification)
집단 A를 B, C, D, E 등 다른 집단으로 오분류 ex. STOP 표지판을 GO 또는 SLOW 등으로 오분류
(3) 출력 오분류 (Targeted Miscalssification)
집단 B, C, D, E 등을 하나의 집단 A로 오분류 ex. STOP 또는 SLOW 표지판을 GO로 오분류
(4) 입력 및 출력 오분류 (Source/Target Misclassification)
집단 A를 집단 B로 오분류 ex. STOP 표지판을 GO로 분류
■ 중독/오염 공격 (Poisoning Attack)
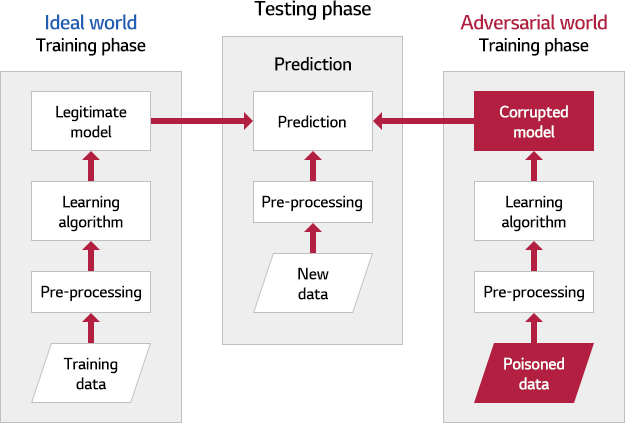
- 모델 학습 시 공격자가 악의적으로 변조된 데이터를 학습 데이터에 삽입함
- 모델 자체를 공격하여 모델에게 영향을 줌
■ 회피 공격 (Evasion Attack)

- 입력 데이터에 최소한의 변조 (perturbation) 을 가해 모델의 정상적인 분류를 방해함
- 사람의 눈으로는 분간하기 어려운 노이즈를 추가하여 이미지 인식에 착오를 일으키게 함
■ 탐색적 공격 (Exploratory Attack)
(1) 모델 전도 공격/학습 데이터 추출 공격 (Model Inversion Attack)

- 모델이 학습한 데이터를 직접 추출함
- 주어진 입력에 대해 출력되는 분류 결과와 신뢰도(Confidence)를 분석하여 역으로 데이터를 추출함
(2) API 기반 모델 추출 공격 (Model Extraction via APIs)

- 공개된 API가 있는 학습 모델의 정보를 추출하는 공격 기법
- 기존 모델이 어떻게 이루어져 있는지 알 수 없어도 API를 통해 얻어진 정보로 기능적으로 비슷한 모델을 구현
공격 기법
- Fast Gradient Sign Method(FGSM)
- Deepfool
- Jacobian-based Saliency Map Attack(JSMA)
- Carlini & Wagner Attack(C&W Attack)
방어 기법
■ Adversarial training
- 특정 공격에 대비하기 위해 모델 학습 시 해당 공격의 적대적 예제를 미리 추가하여 공격에 대한 내성을 갖도록 하는 방어기법 (일종의 data augmentation 방식)
- 장점 : 특정 공격을 매우 효과적으로 방어 가능
- 단점 : 적대적 예제에 대한 robustness가 증가할수록 input에 대한 정확도 감소
■ Defensive Distillation
- 적대적 공격을 위해 활용되는 인공지능 모델의 gradient를 감추는 데 목적이 있음
- 장점 : 적대적 공격에 대응하기 위한 새로운 패러다임
- 단점 : C&W attack에서 취약점이 드러남에 따라 새로운 연구 필요
■ Defense Generative Adversarial Network(Defense GAN)
- 적대적 예제와 인공지능이 생성한 가상 이미지 간 차이를 최소화시켜 적대적 예제로부터 내성을 갖도록 하는 방어기법
- 장점 : 기존 인공지능 모델의 수정없이 공격에 대한 방어 가능
- 단점 : GAN training의 불안정성으로 인해 완벽한 방어 불가능. 학습조건이 성능에 절대적 영향을 미침
■ Fully Homomorphic Encryption (FHE)

- 공격자가 모델의 output 침투를 불가능하게 하여 본질적인 모델방어가 가능하도록 함
- 장점 : 양자컴퓨팅 방식에서도 안전한 양자내성 암호에 해당
- 단점 :인공지능 모델을 위한 완전동형 암호화기술은 기반 연구중
글 : 머신러닝 보안 취약점! 적대적 공격의 4가지 유형/LG CNS
출처 : https://www.lgcns.com/blog/cns-tech/ai-data/9616/
머신러닝 보안 취약점! 적대적 공격의 4가지 유형 - LG CNS
미래학자인 레이 커즈와일(Ray Kurzweil)은 저서 ‘특이점이 온다(The Singularity is near)를 통해 오는 2045년이면 인공지능이 인간의 지능을 넘어설 것으로 예측했습니다. 세간을 충격에 빠뜨렸던 알파
www.lgcns.com
글 : 인공지능과 적대적 공격 (Adversarial Attack)/꼰머의 보안공부
출처 : https://ggonmerr.tistory.com/212
인공지능과 적대적 공격 (Adversarial Attack)
1. 인공지능 - 인간의 학습능력, 추론능력, 지각능력을 인공적으로 구현하려는 컴퓨터 과학 - 인간의 지능을 기계 등에 인공적으로 시연(구현)한 것 - 인공지능 ⊃ 머신러닝 ⊃ 딥러닝 머신러닝 (M
ggonmerr.tistory.com
인공지능보안과 적대적공격/윤수연
출처 : https://velog.io/@cs_tndus/논문인공지능보안과-적대적공격
[논문]인공지능보안과 적대적공격
배경IoT(Internet of Things)의 지능화 및 자율주행 등 인공지능을 융합한 다양한 기술의 실생활 적용실질적인 사용에 주의 필요ex) 자율주행 자동차의 오작동, 인공지능 모델을 통한 개인정보 유출 등
velog.io